Products >> TransReplicator
Products
TransReplicator
TransReplicator is a replica-database creation solution that provides an automated method of creating/refreshing test databases in standard RDBMS environments. It creates and repopulates the replica database by extracting information from an existing database and implements a patent-pending data transformation process to protect the proprietary information contained within that source database. The result is a replica database that has referential integrity and contains all or a portion of the source database's information.
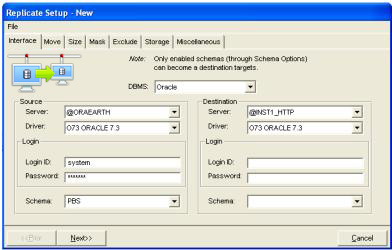
Extract Process definitions include information necessary to support the extract of data and catalog information from the source database as well as the load into the replica (target) database. This includes information such as source database (e.g., name, connection information...), target database, the size of the replica database, data distribution type, extract filters and data transformations.
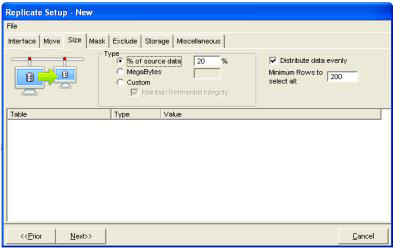
The size of the replica database can be specified
at the database-schema level - in Megabytes or as a percentage of the size of the source database
- or at the table-level - using WHERE clauses, row
counts or percentages of tables.
The extract distribution type can specify whether a 10% extract contains the first 10% of the rows of a driving table or if every tenth row is selected (thus providing an extract that has the same relative distribution of data as found in the source database).
Physical and logical foreign key relationships take the sizing information into account in order to determine which information should be extracted from which tables, thus ensuring that regardless of the size of the extract its referential integrity will remain intact.
Denormalized relationships can be configured
to allow fields that exist in multiple tables to be
masked using the same logic - even though no
database relationship (e.g., foreign key) is defined
between the two fields (e.g., social security number
that resides in multiple tables).
By default, the extract occurs at the database/schema level based upon the requested size but users are allowed to specify selection criteria at the table level if desired (e.g., you may always want to extract 100% of a table containing next-primary-key values).
At the table level they can specify a row count or WHERE clause. They are informed if the extract parameters they specify impact the tools ability to maintain the referential integrity of the source database in the target database.
Data transformations allow the user to specify which columns in the database should have their data transformed during the extract process in order to hide any proprietary data they may contain.
Some examples of proprietary data fields could include customer name, phone number, credit card number, religion, social security number, pricing data, etc... The transformations rules are assigned to columns based upon a set of business rules and require no coding.
A patent-pending process assigned the transformations at the schema level so that all extracts from that schema provide a consistent level of protection, although, additional transformations may be added to a specific Extract Process as needed.
The application provides users with a graphical UI for viewing and analyzing information on the various database objects (e.g., tables, views, procedures, indexes...) in the target and source databases.
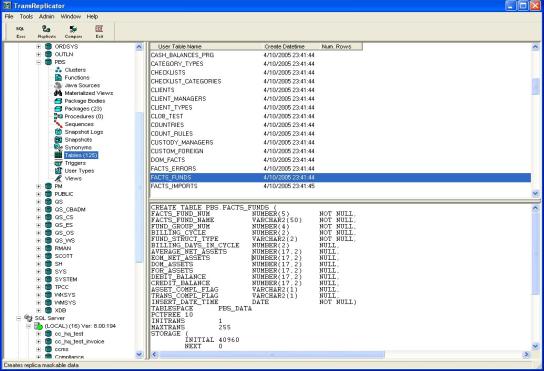
The actual extract process can be run in manual or automated modes. In a manual mode the user selects and runs specific extracts.
In an automated mode the application runs in a batch mode and coordinates with the TRFC web-portal using web services to run and report on scheduled extracts.
During the extract, data transformation algorithms are incorporated in the extract logic thus ensuring no information that you deem proprietary ever leaves the source database.
The extract process utilizes utilities and native bulk loading utilities from each DBMS in order to expedite the data transfer process.
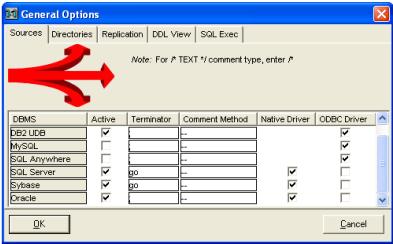
The application works with most standard RDBMS technologies.